
Figure: interaction with the wordle program
For this assignment, you will be implementing a program that lets the user play the game of wordle. It's a word guessing game. If you're not familiar with it, you can try it out at https://www.nytimes.com/games/wordle/index.html and get a quick summary of the rules.
The following shows an interaction with our wordle program. When the program is run, the user provides a filename for a list of 5-letter words and, optionally, a seed number used to determine which word the user has to guess.
Figure: interaction with the wordle program
Above, we're running the program with words from the list-e.txt file and with a seed of 2000 for choosing the target word we're expected to guess. The user enters audio as their first guess. The program's response shows that our guess contains a letter 'd', which is in the correct place. The target word also contains a letter 'o', but our guess doesn't have it in the right place. Every other line is the user's input, with the program's response in the right place. The user makes a few more guesses, learning more about the target word. For their fifth guess, the user accidentally enters a 6-letter word. After two more guesses, the user gets the word right. The program reports the number of guesses it took and then prints out a history of how many guesses it has taken the user on previous problems. I cleared the history before running the program, so it only shows the result of the most recent game, guessing the target in six tries.
The word rules for the wordle game are explained in more detail below. You can also read about the game on the web page linked above and even try out the game yourself.
As in project 2, you'll be developing this project using git for revision control. You should be able to just unpack the starter into the p3 directory of your cloned repo to get started. See the Getting Started section for instructions.
This homework supports a number of our course objectives. See the Learning Outcomes section for a list.
You get to complete this project individually. If you're unsure what's permitted, you can have a look at the academic integrity guidelines in the course syllabus.
In the design section, you'll see some instructions for how your implementation is expected to work. Be sure you follow these rules. It's not enough to just turn in a working program; your program needs to follow the design constraints we've asked you to follow.
You're going to write a program named wordle. It will let the user play the game of wordle. The following sections describe the rules of the game and what the program is supposed to be able to do.
The wordle program will accept one or two command-line arguments. If it is run with one argument, that argument should give the name of a file containing the word list. If it has an additional command-line argument, that should be used as a seed for selecting the word the user will be trying to guess. For example, if the program is run as follows, it will read the word list from list-c.txt and it will use the number 709 as the seed for selecting a word for the user to guess.
$ ./wordle list-c.txt 709If the user provides invalid command-line arguments, the program should print the following usage message to standard error and terminate immediately with an exit status of one. Command-line arguments would be invalid if the user provided too many or if they didn't give at least one argument for the word list filename. They would also be invalid if the second argument was provided but it couldn't be parsed as a positive long integer.
usage: wordle <word-list-file> [seed-number]The word list given as a a text file at program start-up. It must contain a word on each line, and every word must contain exactly five lower-case characters (with no extra whitespace). A word list file can contain between 1 and 100,000 words.
Words in the word list can be in any order, but the word list must not contain duplicates. If the given word list file is invalid, the program should print the following message to standard error and terminate with an exit status of 1. The word list would be invalid if it didn't contain any words, if it contained too many words, if it contained a line that wasn't exactly five lower-case letters, or if it contained a duplicate word.
Invalid word fileIf the program can't open the given word list file for reading, it should print the following error message to standard error, where filename is the name of the word list file given on the command line. After printing the message, it should terminate with an exit status of one.
Can't open word list: filenameIn your implementation, be sure to check for duplicate words after you read in the entire word list. Otherwise, your program will take too long for test cases where there are too many words in the word list.
The program will use a long int seed value to select a target word from the word list. That will be the word the user is required to guess. We will use a little pseudo-random technique here to make it non-obvious what word will be chosen, even if the user has access to the word list.
Let's say there are n words on the word list and they are numbered from 0 (the first word read from the word list file) to n-1 (the last word read from the word list file). The index of the chosen word will be be computed via the following formula. The percent sign represents the mod operations (like it does in C and Java). The multiplier is a large prime number, 4611686018453. Given the limit on the size of the word list, this formula should not overflow the long int type on the common platform.
( seed % n ) * MULTIPLIER % n;If the user doesn't provide a seed value for word selection, you should use the time() function to get the number of seconds since January 1, 1970. This value is a long int on the common platform. Using it as a seed will let the user play the game with a word choice that seems random.
The time() function isn't really part of the standard library, but it's available on Unix machines like the common platform and lots of other systems. You will need to include the time.h header file to use it, and you will need to pass it the value NULL as a parameter. When you call it, it should return the number of seconds since the start of 1970.
After starting the program, it will run interactively. It doesn't prompt the user for a message. This will make the program output a little easier to interpret when we send it to a file, but it means the user needs to know what to do after they start the program.
The user is expected to enter a series of guesses for the target word, one per line. For incorrect guesses, the program will print out a copy of the user's guess with correct letters shown in yellow or green and other letters shown in the default terminal color. In the user's guess, any letter that matches the target word (i.e., the same letter in the same place) will be printed in green. Let's call these the green characters.
If the user has some letter copies of the right letter in the wrong place, they may be printed in yellow. This rule is simple if there's at most one copy of any letter. It gets a little more interesting when there are multiple copies. Let's describe the rule for some character, c that occurs in the target word. The same rule would apply for every character that occurs in the target.
Let's say there are n copies of letter c in the target that are not green characters. There may also be green copies of c but we're not counting those here; we've already decided those will be printed in green. The first (leftmost) n non-green occurrences of c in the user's guess will be printed in yellow. If there are fewer than n, they will all be printed in yellow. If there are more than n non-green occurrences in the guess, then only the first (leftmost) n copies of this character will be printed in yellow.
Some examples will help illustrate the rule for yellow characters. We're using nonsense words here, but we'll pretend they are all in the word list. Let's say the target is "ababa". If the user's guess is "cbcbc", then both occurrences of 'b' will be colored in green since they are a matching character in the right spot. If the user guesses "bbccc" or "cbbcc", then the copy of 'b' in the second spot will be green, but the other occurrence will be yellow. If the user guesses "bbbcc", then the first occurrence of 'b' will be yellow, the second one will be green and the last one will be the default terminal color since there are only two copies of 'b' in the target. If the user guessed "bbcbc", then the first occurrence of 'b' would be in the default color, since both of the remaining occurrences must be green.
If the user enters a guess that's not a valid word from the word list, the program will print the following line to standard output (not standard error). Since the word list can only contain words with five lower-case letters, anything else (including a blank line) would be considered an invalid guess from the user. After printing the "Invalid guess" message, the program will ignore the user's entire line of input and wait for the user to make another guess.
Invalid guessAfter the user successfully guesses the target word, the program will print out a line like the following, giving the number of (valid) guesses (n) the user entered, including their final guess when they guessed correctly. Notice that invalid guesses are not included in the count of the number of guesses.
Solved in n guessesAs a special case, if the user guesses the target on the first try, the program will print the following version of the success message.
Solved in 1 guessAfter printing out this success message, the program will print a history of the user's performance. This report is described below.
After the user guesses correctly, the program will print out a report like the following, showing the number of guesses required on recent games they completed. Each line lists the number of guesses they used. The last line represents ten or more guesses. The number of guesses is printed right justified in a 2-column field. This is followed by two spaces and then a colon for the first nine lines. The last line has a plus, then a space, then a colon. For each line, the colon is followed by another space, then the number of previous puzzles the user solved with the given number of guesses. This number is printed right-justified in a four-column field. For example, the following report shows that the user has played 12 games where they guessed the target word in five guesses.
1 : 0
2 : 2
3 : 3
4 : 8
5 : 12
6 : 40
7 : 32
8 : 7
9 : 2
10+ : 3The score history will be stored in a file named "scores.txt" in the current directory. After the user wins a game, the program will read this file, increment the count for the most recent win, print the report in the format shown above, then save a new copy of the file reflecting the updated count. This "scores.txt" file will contain one line with ten space-separated numbers (so, no space after the last number). These numbers represent the number of games won in 1 guess, 2 guesses, 3 guesses and so on. For example, the table shown above would be saved to the "scores.txt" file like the following:
0 2 3 8 12 40 32 7 2 3Your program isn't expected to handle errors in the score file format. If this file exists, you can assume it contains 10 space-separated non-negative int values.
The program will automatically stop after the user guesses the target word. The user can also type the word "quit" to stop the program immediately, and the program should exit if it reaches the end-of-file on standard input.
If the program exits without a correct guess, the program won't print the success message or the score history report. Instead, it will print the following message, where x is the target word the program selected at the start.
The word was "x"The program may need to change print color as it prints out the response to the user's guess. It can assume the color starts out as the default color for the terminal (probably black), and it should leave the print color as the default at the end of each output line. Within a line, it should change the print color only when necessary, leaving the color the same whenever possible. For example, in printing the following output, it can assume the color starts out at the default for printing the letter 'g'. It should change to green right before printing the 'r' and leave the color unchanged (still green) for the 'i'). It should change to yellow for printing the 'p' then back to the default for the 'e'.

Figure: color changing in program output.
Your program will be implemented four components:
io.c and io.h
This component contains code to help with terminal and file input / output.
lexicon.c and lexicon.h
This component implements the word list.
history.c and history.h
This component implements the score history.
wordle.c
This component contains the main function. With help from the other components, it interacts with the user and plays the game of wordle.
The following figure shows the dependency structure of our components. You can see we've tried to make sure there are no dependency cycles among the components. The wordle component can use the other three, but lexicon can only use the io component (if you want to use it) and io and history don't use any of the other components.
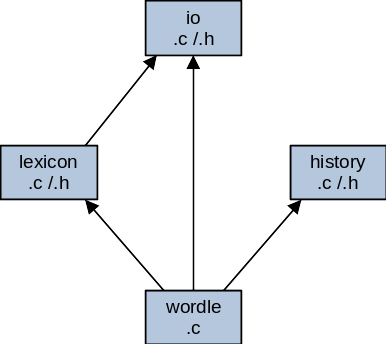
Figure: dependencies among the program's components
You'll implement and use the following functions, to break the program into smaller components and to help simplify your top-level wordle.c component. Remember that functions that are defined in one component and used in another should be prototyped (and documented) in the header. You can add other functions as you like, to help simplify your implementation. Functions that are for internal use in a component should be given internal linkage (static) and should not be prototyped in the header.
The io component will provide the following functions.
bool readLine( FILE *fp, char str[], int n );
This function reads a line of text from the given file. It stores it in str (with a null terminator to mark the end). If the line is longer than n characters, the function reads the whole line but stores just the first n characters. This function should make it easy to read input a line at a time without the possibility of buffer overflow. If the input line is too long, the function automatically discards characters that don't fit. The return value of the function says whether it was able to read a line. If it returns false, then there was not any additional input. If it returns true, then there was an additional line of input.
void colorGreen()
This function changes the text color to green.
void colorYellow()
This function changes the text color to yellow.
void colorDefault()
This function changes the text color back to the default.
The lexicon component will stores the word list and provides functions for using it:
void readWords( char const filename[] )
This function reads the word list from the file with the given name. It detects errors in the word list file and prints an error message
void chooseWord( long seed, char word[] )
Using the given seed, this function chooses a word from the current word list using the procedure described in the requirements. It copies the chosen word to the word[] array.
bool inList( char const word[] );
This function checks the given word to see if it's in the word list. If it is, the function returns true.
The history component just needs to provide one function:
void updateScore( int guessCount )The word list will be stored using static global variables in the lexicon component. You will need an array of strings to store all the words. You may also want some other static global variables to keep up with the list.
The terminal window supports output in different colors. You can switch the text color by outputting what's called an ANSI (American National Standards Institute) Escape Sequence. After you write the following sequence of character codes (shown in hexadecimal) to standard output, any subsequent text you print will show up in green. Then, when you're done printing in green, you can use a different escape sequence to switch to a different color or back to the default color.

The following sequence will switch the text color to yellow.

The following sequence of character codes will switch the text color back to the default.
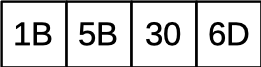
Different terminal software will render these print colors differently. On some terminals, the yellow text may look more like orange, and on some, the green text will look a little more blue. That's OK. As long as you use these codes to switch colors and your output files match the expected files, your solution should pass our tests.
How do you print a sequence of arbitrary character codes to the terminal? There are a few ways to do it. You can use putchar() to write out any character code you want. Or, you can use printf with the %c conversion specifier to write out any code. Finally, remember that there is a way to write out any character code you want as part of a format string. We talked about that in lecture 2.
Don't use any global variables other than the ones you'll use to represent the list of words in the lexicon component. Functions should be able to get everything else they need from their parameters passed to them.
Be sure to avoid magic numbers in your source code. Use the preprocessor to give a meaningful name to all the important, non-obvious values you need to use. For example, you can define constants for the size of the list of scores and the required length of a word.
For constants that are explained right in the line of code where they occur, I wouldn't call these magic numbers. For example, if you need to read two integers, you might write something like the following. Here, the value 2 wouldn't be considered a magic number. It's explained right there in the format string, where we say we'd like to parse two integers, and changing the format string would require changing the number 2. Defining a named constant to use here would probably just make the program harder to maintain.
if ( fscanf( stream, "%d%d", &a, &b ) != 2 ) {
....
}You're not required to have an efficient implementation of your inList() function and searching for duplicate words. This can be slow if the word list is very long and the user makes a lot of guesses; test case 09 demonstrates this.
For extra credit, you can sort the word list near the start of program execution. This will let you find duplicate words efficiently, and you will be able to implement your inList() function using binary search.
Be sure to select the target word before you sort the word list, since the choice of the target depends on the original ordering of words in the word list file. You will need to implement your own efficient sort for the word list (i.e., don't use one of the sorts built into the standard library). You can write your own quicksort, mergesort, heapsort, whatever you want as long as it can be expected to run in O( n log n) time. You can add another non-static function to the lexicon component for performing this sort, if you want.
If you do the extra credit, be sure to look for duplicate words in the word list after you sort the list. This will let you find duplicates in linear time
You will also need to implement your own binary search in your inList() function (don't use the one from the standard library). With these changes, your implementation should be much faster on test case 9.
You get to create your own Makefile for this project (called Makefile with a capital 'M' and no filename extension). Its default target should build your wordle program, compiling each source file to an object file, then linking to produce an executable. Your Makefile should correctly describe the project's dependencies, so if just one source file changes it knows how to rebuild just the parts of the project that depend on that source file.
The wordle program should be your makefile's default target. You should be able to rebuild it by just entering make:
$ makeAs in the previous project, your Makefile must have a clean rule, to remove any temporary files in the project (object files, executables, temporary output files, etc). If you run make as follows, it should delete just the temporary files:
$ make cleanThe starter includes a test script, along with test input files and expected outputs for several test cases. When we grade your program, we'll test it with this script, along with a few other test cases we're not including with the starter. To run the automated test script, you should be able to enter the following:
$ chmod +x test.sh # probably just need to do this once
$ ./test.shThis script will try to automatically build your program using your Makefile and see how it behaves on the test inputs.
You probably won't pass all the tests the first time, and the test script won't work until you have a working Makefile. Until then, you can run tests yourself. You can use commands like the following to compile your program (although your Makefile will be more efficient, compiling source files separately and then linking them together):
$ gcc -Wall -std=c99 -g wordle.c lexicon.c history.c io.c -o wordleYou can, of course, try out the program entering your own input from the terminal. This is probably the best way to get started testing your program.
If you want to try your program out on just one of the provided test cases, you can enter commands like the following. The test script reports how it's running your program for each test. Here, we're doing the same thing as test 4. We're deleting the scores.txt file first, then running the program with list-d.txt as the word list and 200 as the seed. We're telling it to write the output to a file named output.txt. After running the program, we check to make sure it exited successfully (it should for this test case). Then, we compare its output to the expected output.
$ rm -f scores.txt
$ ./wordle list-d.txt 200 < input-04.txt > output.txt
$ echo $?
0
$ diff output.txt expected-output-04.txtTest 8 starts with a non-empty score file, and the program should update it after the player wins. Here, we're checking everything we do above, but we're also setting up the initial scores.txt file and checking its contents afterward.
$ echo "0 0 0 2 5 3 1 2 0 0" > scores.txt
$ ./wordle list-e.txt 5 < input-08.txt > output.txt
$ echo $?
0
$ diff output.txt expected-output-08.txt
$ diff scores.txt expected-scores-08.txtTest 14 is an error test. We can try it out as follows. After running the program, we should get an error for the exit status and the program should print the right message to standard error.
$ ./wordle list-i.txt 1 < input-14.txt > output.txt 2> stderr.txt
$ echo $?
1
$ diff stderr.txt expected-stderr-14.txtWe've prepared several test cases to help you make sure your program is working right. The test cases all use the following sample word lists:
list-a.txt is a file containing just one word.
list-b.txt is a file containing just two words.
list-c.txt is a file with 11 common English words.
list-d.txt is a file with 478 common English words, taken from this website
file-e.txt is a file with 4954 English words, some of them not so common, taken from the Linux dictionary file at /usr/share/dict/words.
list-f.txt is a large word list, containing 50,000 randomly generated words.
list-g.txt is a list of made-up words with lots of repeated letters.
list-h.txt is an invalid word list. It contains a word with just four letters.
list-i.txt is an invalid word list. It contains a word with a capital letter.
list-j.txt is an invalid word list. It contains too many words.
list-k.txt is an invalid word list. It contains a duplicate word.
The test driver uses the files above for several different tests. Most of the following tests are run without a pre-existing scores.txt file, so your program must create it if the user wins. A couple of the tests start with a non-empty score file, so your program must increment one of the existing scores.
This test just enters quit to terminate the program immediately.
This test enters a guess that doesn't match any letters from the target word, then exits. The target word should be "cramp".
This test enters a few guesses with letters that are in the target but not in the right place. The target word should be "after".
This test enters a few guesses with letters that match the target word and are in the right place. It ends at the end-of-file (rather than a quit command). The target word should be "study".
This test enters several invalid guesses (e.g., too long, too short, not in the word list). The target word should be "civil".
This test enters the target word on the first try. It's the first test where you have to report the score history and increment one of the counts.
This test makes several wrong guesses, then guesses the right word on the 6th try. It's the same example shown at the start of the assignment.
The target for this test is "beeps". The input includes several guesses with 'e' characters in the right places or in the wrong places. It starts with a non-empty scores.txt file containing "0 0 0 2 5 3 1 2 0 0".
This test makes 8000 guesses using a word list of 50,000 randomly generated words. It may take several seconds to run, depending on how you implemented the inList() function.
This test uses randomly generated words to test the coloring of letters when there are multiple copies of the same letter. The target word should be "aaabb".
This test starts with a scores.txt file that already contains a 1 for every count. It matches the target after six guesses, so only the score for count 6 should be increased.
This test starts with a scores.txt file that already contains a 10 for every count. It matches the target after twelve guesses, so the maximum score value should be incremented.
This is an error handling test. It uses a dictionary with a word that's too short.
This is an error handling test. It uses a dictionary with a word that's has a non-lowercase character.
This is an error handling test. It uses a dictionary with too many words.
This is an error handling test. It uses a dictionary with a duplicate word.
If the user doesn't provide a seed value on the command-line, the program will use the number of seconds reported by the time() call. This is described in the requirements, but the automated testing script doesn't include a check for this behavior.
To test this behavior yourself, you can check the current number of seconds (since January 1, 1970) then quickly run your program. This should tell you what seed it will get when it calls time(). Try running your program as follows:
$ date +%s.%N; ./wordle list-e.txt
1646137207.938095033
quit
The word was "flips"Above, I'm running the date command, reporting the number of seconds along with a 9-digit fraction. When I ran this, I got 1646137207 as the number of seconds. The semicolon, then ./wordle should start my program immediately after running the time command, so it will (probably) start within the same second as the date command. This lets me know what value it should get when it calls time().
I quit the wordle program to see what word it chose from list-e.txt. Then, I run it again with the number of seconds I got from date command as the seed value. Again, I quit after my program starts so I can check the word it selected. It's the same one I got when I let it use time() for the seed value, so this makes me think my program is doing the right thing when I don't provide a seed.
./wordle list-e.txt 1646137207
quit
The word was "flips"When you're testing like this, there's a small chance that the wordle program won't start within the same second as the date command, so it may get a different seed value than the number of seconds reported by date. That's why we're asking date to report a fractional number of seconds. If we're very close to the start of the next second when we test this, then it's more likely our wordle program won't get to start in the same second reported by the date command. That's what I'm showing below. Here, I'm pretending we were only 1/1000 of a second from the start of the next second when I ran this command. In this case, wordle didn't get 1646137207 when it called time(). It started in the next second, 1646137208.
$ date +%s.%N; ./wordle list-e.txt
1646137207.999000000
quit
The word was "makes"If you run a test like this and you get a value that's close to the end of the second, you can just ignore that test and try again.
The grade for your program will depend mostly on how well it functions. We'll also expect it to have a working Makefile, to compile cleanly, to follow the style guide and to follow the design given for the program.
To get started on this project, you'll need to clone your NCSU github repo and unpack the given starter into the p3 directory of your repo. You'll submit by adding and committing files into your repo and pushing the changes back up to the NCSU github.
You should have already cloned your assigned NCSU github repo when you were working on project 2. If you haven't already done this, go back to the assignment for project 2 and follow the instructions for for cloning your repo.
You will need to copy and unpack the project 3 starter. We're providing this file as a compressed tar archive, starter3.tgz. You can get a copy of the starter by using the link in this document, or you can use the following curl command to download it from your shell prompt.
$ curl -O https://www.csc2.ncsu.edu/courses/csc230/proj/p3/starter3.tgzTemporarily, put your copy of the starter in the p3 directory of your cloned repo. Then, you should be able to unpack it with the following command:
$ tar xzvpf starter3.tgzOnce you start working on the project, be sure you don't accidentally commit the starter to your repo. After you've successfully unpacked it, you may want to delete the starter from your p3 directory, or move it out of your repo.
$ rm starter3.tgzIf you've set up your repository properly, pushing your changes to your assigned CSC230 repository should be all that's required for submission. When you're done, we're expecting your repo to contain the following files. You can use the web interface on github.ncsu.edu to confirm that the right versions of all your files made it.
wordle.c : Main implementation file, written by you.
history.c / history.h : Code for the score history, written by you.
lexicon.c / lexicon.h : Code for the word list, completed by you.
io.c / io.h : Code for the io component, written by you.
Makefile : The project's Makefile, created by you.
list-*.txt : Word list input files, provided with the starter.
input-*.txt : Test user input files, provided with the starter.
expected-output.txt : Expected (stdout) output files for the test cases, provided in the starter.
expected-stderr-*.txt : Expected stderr output for the error tests, provided in the starter.
expected-scores-*.txt : Expected score files for test cases where the user wins.
test.sh : test script, provided with the starter.
.gitignore : a file provided with the starter, to tell git not to track temporary files for this project.
To submit your project, you'll need to commit your changes to your cloned repo, then push them to the NCSU github. Project 2 has more detailed instructions for doing this, but I've also summarized them here.
Whenever you create a new file that needs to go into your repo, you need to stage it for the next commit using the add command:
$ git add some-new-fileThen, before you commit, it's a good idea to check to make sure your index has the right files staged:
$ git statusOnce you've added any new files, you can use a command like the following to commit them, along with any changes to files that were already being tracked:
$ git commit -am "<meaningful message for future self>"Of course, you haven't really submitted anything until you push your changes up to the NCSU github:
$ git pushChecking jenkins feedback is similar to the previous homework. Visit our Jenkins system at http://go.ncsu.edu/jenkins-csc230 and you'll see a new build job for project 3. This job polls your repo periodically for changes and rebuilds and tests your project automatically whenever it sees a change.
The syllabus lists a number of learning outcomes for this course. This assignment is intended to support several of theses:
Write small to medium C programs having several separately-compiled modules.
Explain what happens during preprocessing, lexical analysis, parsing, code generation, code optimization, linking, and execution. Explain the function and organization of relevant, intermediate formats, including pre-processor expanded source code, object files and executables. Compare and contrast the build and execute behavior between C and Java.
Identify errors that can occur during various compilation phases, identify relevant error messages and warnings, and appropriately correct these errors.
Correctly identify error messages and warnings from the preprocessor, compiler, and linker, and avoid them.
Find and eliminate runtime errors using a combination of logic, language understanding, trace printout, and gdb or a similar command-line debugger.
Interpret and explain data types, conversions between data types, and the possibility of overflow and underflow.
Explain, inspect, and implement programs using structures such as enumerated types, unions, and constants and arithmetic, logical, relational, assignment, and bitwise operators.
Trace and reason about variables and their scope in a single function, across multiple functions, and across multiple modules.
Use the C preprocessor to control tracing of programs, compilation for different systems, and write simple macros.
Write, debug, and modify programs using library utilities, including, but not limited to assert, the math library, the string library, random number generation, variable number of parameters, standard I/O, and file I/O.
Use simple command-line tools to design, document, debug, and maintain their programs.
Use an automatic packaging tool, such as make or ant, to distribute and maintain software that has multiple compilation units.
Use a version control tool, such as subversion (svn) or Git, to track changes and do parallel development of software.
Distinguish key elements of the syntax (what's legal), semantics (what does it do), and pragmatics (how is it used) of a programming language.
Describe and demonstrate how to avoid the implications of common programming errors that lead to security vulnerabilities, such as buffer overflows and injection attacks.